An Associated Press article on ESPN outlines how the Division I men’s basketball committee wants to make bracket construction to be more fair [Link]. At present, there are 68 teams with no plans to expand the field. However, the committee has many decisions to make when it comes to who makes it in and who doesn’t as well as the seed and the region. All of this together determines potential matches. Previously, the committee tried to entirely avoid rematches in the first few rounds of the tournament. Given the large number of potential match-ups depending on who wins and loses, this constrained the bracket (possibly too much).
“There have been years where we’ve had to drop a team or promote a team; there was even a year where teams dropped two seed lines. We don’t feel that’s appropriate.” – Ron Wellman, the athletic director at Wake Forest
The article doesn’t exactly hint that integer programming could be used to solve this problem, but that’s the next logical step. In fact, there is a paper on this! Cole Smith, Barbara Fraticelli, and Chase Rainwater developed a mixed integer programming model (published in 2006, back when there were 65 teams) to assign teams to seeds, regions, and pods (locations). The last issue is important: constructing the bracket is intertwined with assigning the bracket to locations for play. For example, four teams in a region in the field of 64 (e.g., a 1, 8, 9, and 16 seeds) must all play at the same location to produce a single team in the Sweet 16.
The Smith et al. model minimizes the sum of the (then) first-round travel costs (the round of 64), the (then) expected second-round travel costs (the round of 32), and the reseeding penalty costs while considering typical assignment constraints as well as several side constraints, including:
- no team plays on its home court (except in the Final Four – that location is selected before the tournament),
- no intra-conference match-ups occur before the regional finals (what was the fourth round). This is the constraint that may be relaxed somewhat in the new system. Therefore, this existing model can be used to make brackets in the proposed new system.
- the top-seeded team from each conference must be assigned to a different region as the second- and third-highest seeded teams from that conference.
- the best-seeded teams should be assigned to nearby pods (locations) in the first weekend (a reward for a good season!), and
- certain universities with religious restrictions must be obeyed (e.g., Brigham Young University cannot play on Sundays).
It is worth pointing out that this model assigns the seeds to teams. A team that could be considered as an 11-13 seed would be assigned its seed (11, 12, or 13) based on the total cost of the system. That may seem like it’s unfair on some level, but it might be better for a team to be a 13 seed and play nearby than a 12 seed but have to travel an extra 1000 miles. (Note: Nate Silver and the 538 team use travel distance in their NCAA basketball tournament prediction model because distance matters). Flexible seeds allows for a bracket that gives more teams a fair shot at winning their games, but too much flexibility would be unfair to teams. The Smith et al. model allows for some flexibility for 6-11 seeds.
The mixed integer programming model by Cole Smith, Barbara Fraticelli, and Chase Rainwater already addresses the committee’s concerns, which begs the question: why isn’t the committee using integer programming??
OK, it’s probably pretty easy to think of a few reasons, and none of them involve math. One concern is that the general public seems to distrust models of any kind. This may be because models are black boxes to non-experts. This lack of transparency makes it hard to generate any kind of public support (Exhibit A: the debate about the model for the BCS football rankings). Perhaps marketing could improve buy in (“The average team traveled 500 miles fewer this year than last” or “Five teams had to travel across all four US time zones last year, and none had to do so this year.”) A better suggestion may be to give a few of the top integer programming solutions to the committee, who can then use and adapt (or ignore) the solutions as they see fit. Currently, the committee looks at several rankings (including the LRMC method, last time I heard), so they are already using math models to influence the decisions ultimately made by humans.
How would you use operations research and math modeling to improve the tournament selection and seeding process?
Reference:
Smith, J.C., Fraticelli, B.M.P, and Rainwater, C., “A Bracket Assignment Problem for the NCAA Men’s Basketball Tournament,” International Transactions in Operational Research, 13 (3), 253-271, 2006. [Link to journal site]

 nodes before it certifies that it is infeasible (not polynomial time). The paper is very short and provides the proof (see the reference below).
nodes before it certifies that it is infeasible (not polynomial time). The paper is very short and provides the proof (see the reference below).

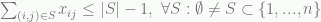
 if node j is visited after node i. The c values are the costs/distances. Assume that c is symmetric here. The second line makes sure that each city/node is visited once. The last line shows the subtour elimination constraints.
if node j is visited after node i. The c values are the costs/distances. Assume that c is symmetric here. The second line makes sure that each city/node is visited once. The last line shows the subtour elimination constraints. 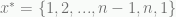
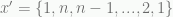 .
. if
if  and 0 otherwise.
and 0 otherwise.
 if node i is the kth node in the tour and 0 otherwise. Parts of the IP model above would have to be reformulated, but I’ll omit that here. There are n identical solutions (2n if the costs are symmetric). The following two tours are different solutions to the model that are the same tour in the problem:
if node i is the kth node in the tour and 0 otherwise. Parts of the IP model above would have to be reformulated, but I’ll omit that here. There are n identical solutions (2n if the costs are symmetric). The following two tours are different solutions to the model that are the same tour in the problem: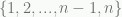


 . In fact, the LP relaxation contains the ray
. In fact, the LP relaxation contains the ray 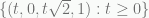 . Therefore, the LP relaxation is unbounded.
. Therefore, the LP relaxation is unbounded.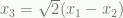 ) can only happy when both sides are zero for integer variables. Therefore, we know that
) can only happy when both sides are zero for integer variables. Therefore, we know that 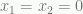 or
or  and that
and that  in either case. Putting this together, there are only two feasible points in the integer programming model: (0, 0, 0, 1) and (1, 1, 0, 0). As you can see, it is not unbounded.
in either case. Putting this together, there are only two feasible points in the integer programming model: (0, 0, 0, 1) and (1, 1, 0, 0). As you can see, it is not unbounded.

