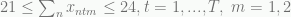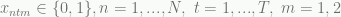Last month, I had the pleasure of meeting Yakov Ben-Haim and talking with him at length about info-gap decision theory. He used an example of squirrels foraging for nuts to illustrate the types of problems for which info-gap decision theory models are useful.
A squirrel needs calories to survive, and nuts provide the perfect source of calories. The squirrel has a decision to make: where should the squirrel go to forage for nuts? Different foraging locations have different potentials for nut payoffs. They also have risks (not enough food). Foraging in a new location may carry highly uncertain risks that are impossible for the squirrel to estimate (being hit by a car, eaten by a wolf, etc.)
The squirrel has two options: the squirrel can hunt in the usual area where he can obtain n nuts with certainty or he can try a new location where he has a probability P of obtaining N nuts (with N > n) and a probability (1-P) of obtaining zero nuts. Let’s say that N and P are wild guesses.
Let’s say that the squirrel is an optimizer and decides to build a decision tree to maximize the number of nuts he can collect. Using basic decision analysis, he devices that he should choose the new location if PN>n.

The squirrel's decision tree. Squirrels don't really make decision trees, do they?
If the squirrel needs to collect n nuts to survive, then maximizing is nuts (pun intended. Sorry!) Staying with the status quo guarantees survival, even if P and N are large. The payoff for the new location may be greater, but there is a 1-P chance that the squirrel would starve. The traditional decision tree is not robust to the squirrel’s desire to survive (neither is darting in front of cars on the highway, but I digress).
On the other hand, if the squirrel needs to collect N nuts to survive, then staying with the status quo guarantees the squirrel’s demise. The new location is worth a look no matter how risky.
In both of these scenarios, the squirrel isn’t really maximizing the subjective expected nuts that he can collect–he really wants to maximize the probability of meeting his nut threshold (the one that guarantees survival). This is a satisficing strategy (although not dissimilar from an optimizing strategy with a moving threshold). The satisficing strategy is a better bet for the squirrel than the optimization strategy in this decision context. The squirrel doesn’t always need to know the exact probabilistic information to make a good decision, as illustrated above. In fact, he can have absolutely no idea what N and P would be to find an effective nut foraging strategy–even when there is severe uncertainty.
The idea of a squirrel building a decision tree is, of course, ludicrous. But it makes the point that what we should rethink our traditional optimization models so make sure they fit the real decision criteria on hand. Info-gap decision theory thus focuses on satisfying a given acceptable level of what is traditionally considered the objective function value and instead optimizing robustness. It also has philosophical implications for how one views certainty.
I’ve been looking more closely at robustness lately. I won’t abandon my optimization models, but I will acknowledge that including robustness in certain scenarios leads to decisions that more accurately reflect the criteria at hand and decisions that could be counter-intuitive.
Yakov Ben-Haim can explain this much better than I can, so I’ll refer you to his blog about info-gap decision theory and his article about foragers in the American Naturalist if you want to learn more.

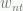 : preference weight for student n and theme t (either 0, 1, 2, 4, or 8).
: preference weight for student n and theme t (either 0, 1, 2, 4, or 8). : 1 if student n is assigned to theme t in module m.
: 1 if student n is assigned to theme t in module m.